【中小企業や個人商店様向け】外注しなくてもOK!異常検知システム自作のすすめ。
こんにちは。mocal designの佐藤です。
過去ブログ記事のなかでディープラーニングや機械学習を用いたデータ分析(クラスタリング、分類、回帰、時系列分析)について説明してきました。
当社サービスを利用するお客様からも反響を多くいただいているため、本日は機械学習の異常検知について説明します。
わかりやすい例としては、車やロボットにカメラやセンサーがついていて、そのセンサーが情報を集めるなかで異常を検知するという使い方をされるのが一般的ですね。
私の本業であるブランド品買取業界でよくある使われる事例としては「AI査定」でブランド品の贋作を見抜くという使われ方をします。
ルイヴィトンのモノグラムというバッグの偽物を見抜くとしましょう。
当社にはルイヴィトンのモノグラム柄の商品はたくさんあるので、本物の画像はたくさん手に入ります。
恥ずかしながら、過去に偽物のルイヴィトンを買い取りしてしまったことがあるので、偽物画像は数点使えるものがあります。
そのように正常のデータは沢山ある。しかし、異常のデータはほとんどないという場合にも異常検知は使えます。
この記事をご覧になっている方の多くは何らかのビジネスをされていると思います。
「ご自身のビジネスに関わる数値の異常値」または「さまざまな属性情報や特徴の異常値」を知りたいという時はございませんか?
実はこのようなケースはどの業界にも多々存在しますので、弊社ではデジタル化を進めている中小企業や商店様に対して自作の異常検知技術導入をおすすめしています。
異常検知ツールを使えば、商取引で発生する数値の推移で異常値を発見するということもできるでしょう。何らかの推移で考えたとき、「急激な変化」と「ゆるやかな変化」にわけることができます。
ゆるやかな変化を正常として急激な変化を異常とした場合、通常の分類ではそれぞれのデータ数がそれなりに沢山必要となります。
当然機械学習の分類では異常のデータをみたうえで正常と異常を区別する方法で中身を学習されるからです。
実は異常データを集めるなかでリーマンショックやコロナショックといわれるような急激な変化が何度も発生するということは多くありません。
通常通りの運用がされている日数のほうが大半なのです。
そうした場合に分類モデルで分類するとしたとき、(異常がすくないと)モデルとしては「常に正常ですよ」と言ってしまうモデルが出来上がってしまいます。
本質的にはここで以前説明した「分類」と中身は同じですが、異常検知と分類とでは問題設定が少し違います。
異常検知は異常のサンプルが少ないなかで、正常と異常を分けるというときに使える問題設定なのです。
これからは具体的にどのような方法で異常検知をしているかお伝えしていきます。
主に弊社では以下3つの手法で異常を検知しています。
①Classification(分類による手法)
②Probabilistic(確率による手法)
③Reconstruction(再構成)
まずはClassification(分類による手法)からお伝えしていきましょう。
Classification(分類による手法)
以前書いた「分類」の話でサポートベクターマシン(SVM)という手法をお伝えしました。
分類のサポートベクターマシン(SVM)について知りたい方はこちらをご覧ください。
サポートベクターマシンの仲間でOne Class SVMというものがあります。
One Classという名の由来は「正常データだけは持っている。しかし異常データは持っていない」というとき正常データのクラスだけを使って分類(SVM)を行うことからきています。
今までのサポートベクターマシンはAグループとBグループがあって、その間に境界線をひくというものでした。
しかし今回は先述の青(正常)の情報は得られています。
赤(?)の情報はありません(またはあっても少ない)という状況で考えてみましょう。

その場合、方法としてはAを丸で囲んであげます。
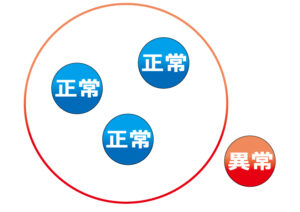
丸の外に発生したものはBであると定義する。
そのやり方をOne Class SVMまたはOC-SVMと言います。
つまり、正常データをかこむ円を計算して境界線をつくるアルゴリズムです。
次にProbabilistic(確率による手法)を説明しましょう。
Probabilistic(確率による手法)
これは先ほどのような境界線を引く手法でありません。
あるゲームを1,000名の方にやってもらうとしましょう。
0から100までのスコアがでるゲームで平均点が60点だとします。
60点の人が1番多い
40点から下は少なくなる。
80点から上は少なくなっていくとしてください。
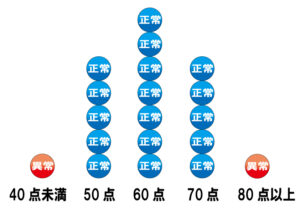
確率による手法とは、確率が一定値以下のものを全部異常にみなすという手法です。
80点以上が5%、40点未満が5%としましょう。
上下の5%を異常とみなしたいという場合にこのモデルは使えます。
つまり80点から上、40点から下を異常と教えてくれるモデルがProbabilistic(確率による手法)なのです。
この手法をKDE GMMとも言います。
KDE GMMのなかのGMMはGaussian Mixture Modelの略でガウス分布(正規分布)のなかで特に振る舞いのおかしいデータを探すということです。
最後にReconstruction(再構成)について説明します。
Reconstruction(再構成)
Reconstructionはオートエンコーダを用いる手法。
オートエンコーダとは前回説明したニューラルネットワークのひとつです。
入力したデータを一度小さくして、重要な特徴を残したのち、再度もとの次元に復元する仕組みのことです。
ちなみによく聞くディープラーニング(深層学習)はオートエンコーダの開発によって完成した技術です。
もっとわかりやすく説明すると、1、2、3・・・8、9、0という数字が手書きで書かれた文字を機械が判断するような技術がオートエンコーダを用いたものとなります。
ディープラーニングについて知りたい方はこちらをご覧ください。
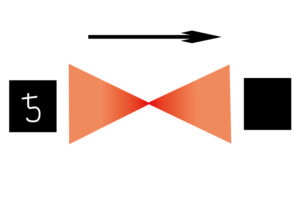
5と手書きした文字画像を入力します。
それを前回説明した畳み込みを行い、低次元に次元圧縮していきます。
画像を小さくする演算をして不要な情報を削減していくと思ってください。
前回の話で言えば、3×3のフィルターを用意して左から右に特徴を抽出していくようなイメージでしょうか。
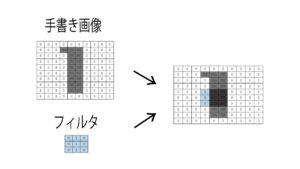
次に次元圧縮したものをまた戻すという操作をして5であると判断します。
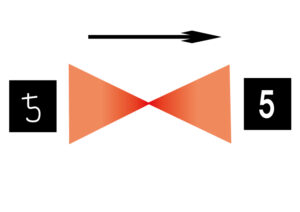
この砂時計の形をしたような構造を持つものをConvolutional Autoencoder(畳み込みオートエンコーダ)と言います。
このオートエンコーダを使う狙いは、圧縮した特徴を得ることによって小さくしてから再度膨らませてあげても元に戻ることができるような情報を得なさいという指示を与えることができる点です。
基本は5と書いたような数字を入力して、圧縮後膨らませた後に5という数字を正解値として返すオートエンコーダを学習します。
実際に手書きの数字をたくさん与えて、学習の精度を上げていくモデルがあります。
このような技術をReconstruction(再構成)と言います。
ここからはReconstructionを使ってどう異常検知するかを考えましょう。
手書きの数字を判別するモデルにアルファベットを入力として与えるとどうなると思いますか?
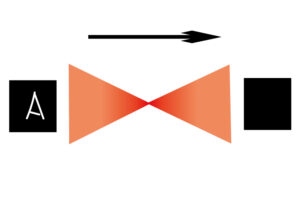
Aという文字を入力すると「よくわからない」結果を吐き出すことになります。
ここで発生する入力と出力の誤差を学習して、誤差がしきい値以上ならこの入力は異常だと判別することになります。
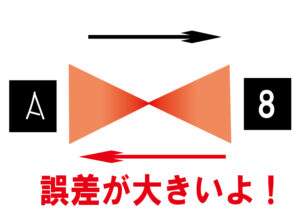
その性質を利用した方法がReconstruction(再構成)を用いた異常検知なのです。
異常検知手法ごとのモデル紹介。
本日は以下の異常検知手法を紹介しました。
①Classification(分類による手法)
②Probabilistic(確率による手法)
③Reconstruction(再構成)
上記のなかにはこのほかにも沢山の手法が存在しますが、今回はそれぞれにひとつずつ異常検知モデルを説明しました。
Classification(分類による手法)のOne Class SVMというモデルを使えば、属性情報から異常を検知することができます。
Probabilistic(確率による手法)のKDE GMMというモデルを使えば数値の異常値を判別できます。
Reconstruction(再構成)のConvolutional Autoencoderを使えば画像から異常値を判別できます。
冒頭で話したようなブランド品の真贋判定にはConvolutional Autoencoderが有効です。
本物と偽物の判別の場合、偽物の画像を入れると誤差が大きくなるということから容易に判別できるでしょう。
本日は異常検知について簡単に説明いたしました。
おわかりいただけましたでしょうか?
当社では本日説明した異常値検知を
・numpy (数値計算のライブラリ)
・Pandas(データ解析を支援するライブラリ)
・Matplotlib(グラフを描くライブラリ)
・scikitlearn(クラスタリング、回帰、次元削減、分類に使うライブラリ集)
・PyTorch、TorchVision(物体分類用のモデルを作成する際に利用)
を使って行います。
「当社(当店)も異常検知に興味がある」
「話だけ聞いてみたい」
という方はビデオサービスZOOMを使って20分の無料コンサルをすることができますので、是非ホームページのCONTACTページからお問い合わせください
(通常コンサルは30分5,000円です)。
小平でホームページ制作、経営コンサルティング
mocal design 佐藤 大樹
東京都小平市南町1-27-10